

I’ve created more ML models for disambiguating key petroleum systems concepts in text. These are needed when creating algorithms to parse text to detect patterns and extract entities to improve search (Information Retrieval), Visual Analytics or populate a KnowledgeGraph.
For example, ‘migration’ (migrates, migrated, migrating) to go with the ‘source’ (as in source rock) model (94% accurate) from last month article here
Using one thousand public domain petroleum geoscience sentences, I labelled those where ‘migration’ is used in the sense of Hydrocarbon Migration and those where it is not. Using an ensemble method combining Support Vector Machine (SVM) and Multinomial Bayes classifiers with word order a Machine Learnt (ML) model was created which achieved a 96% F1 Score (see Figure 1).
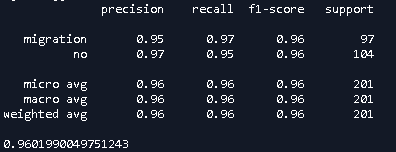 Fig 1 – Precision, Recall and F1 Score for ‘migration’
Fig 1 – Precision, Recall and F1 Score for ‘migration’
Hyperparameters
One curious observation is that the hyperparameters that work for disambiguating one term (e.g. source), are not the same as those for another (e.g. migration). After some analysis I postulate that (training sentences being of relatively equal length), it is the variation in training sentence structure specific to a term. This means that some hyperparameters are ‘better’ for one term than another, even when using the same classification models.
This Word Sense Disambiguation (WSD) model is needed because even in geoscience/petroleum geoscience literature, ‘migration’ has many senses. For example:
Hydrocarbon Migration
“…likely routes for this migration include the upper cretaceous reservoir intervals and steep strike slip faults extending from basement through the cretaceous…”
Other uses for Migration in Geoscience
…tabular sand-body produced by lateral migration of the point bar…
…Post migration Seismic Impedance inversion is very commonly done…
..for large basins with continuous depocenter migration, such as…
…at the leading edge of the Caribbean Plate as it migrated from the Pacific…
…with its total dependence on laterally migrating salt…
etc.
Without these models, any extraction of these concepts within text is likely to lead to false positives (impacting accuracy) and false negatives (impacting completeness).
As the models are saved as binary pickle in Python, a single line of code in Python is all that is required to make a prediction given a passage of text:
prediction = ensemble_migraton.predict([line of text])
Where ensemble_migration is the pickled_model
If the prediction is ‘no’, then the code/processor can skip that occurrence of the term as it is ‘not the sense you are looking for‘.
At these levels of accuracy (94-96%) the ML models are close to human-like performance, but capable of making predictions on millions of sentences in short order, far exceeding our cognitive limitations.

Leave a comment