
Understanding a word by the company it keeps (Firth 1957) and the Distributional Hypothesis (Harris 1954) – words that occur in the same contexts tend to have similar meanings – are concepts that have been with us for over a half a century. However, in the past few years we have seen a remarkable body of research and publicly available OpenSource software code and models that have revolutionized Natural Language Processing (NLP). This allows reading, comprehension, natural language generation, machine translation, question answering and summarization capabilities we have not seen previously.
Creating unsupervised word vectors (geometric encodings) through simple counting methods (frequency of terms (keywords) in a document, sentence, co-occurring with another term) were limited in their ability to capture semantic information. Mikolov et al (2013) published a prediction model for neural word vectors (text embeddings or word embeddings) using a shallow neural network which has been widely used by practitioners and formed the basis for much of the subsequent research.
When training on a text corpus (such as Wikipedia), the results of performing operations on vectors has often been startling in its ability to detect nuances of language and meaning. For example, taking the vector KING and subtracting the vector MAN gives the ‘answer’ of QUEEN. Vector transitions also allow comparisons such as FRANCE is to PARIS what GERMANY is to.. with the model capable of giving the answer BERLIN.
Taking a geoscience example, using 100 years of the Society of Economic Geology (SEG) as a training set, when adding the two vectors HYDROTHERMAL and GRANITE the resulting model gave the most similar vectors shown in (Fig 1). These make a lot of geological sense given the input of a process (hydrothermal) plus a rock (granite). This raises all sorts of possible uses and applications.
 Fig 1 – Cosine similarity of vectors to ‘hydrothermal’ + ’granite’
Fig 1 – Cosine similarity of vectors to ‘hydrothermal’ + ’granite’
Other uses for example could be in the area of competitive intelligence, to cluster and infer the behaviour of different companies using neural word vectors. Figure 2 shows oil company attitude towards risk and opportunity from almost 100,000 literature articles.
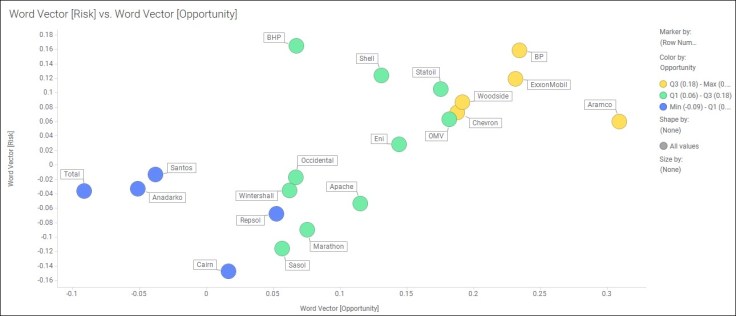
Fig 2 – Similarity (cosine) of company name vectors to vectors of opportunity (x-axis) and risk (y-axis)
At least based on published content, some companies appear far more ‘opportunity’ focused than others, whilst others appear more ‘risk’ focused. Plotting through time may yields trends, as Weick indicates in organizational research, the ‘process of becoming’ is often more interesting than the ‘state of being’. Using unsupervised machine learnt vectors for uses cases like this is a far more sophisticated approach than simply rule-based counting of the frequency of occurrence of terms or a taxonomy of terms.
Applying to geoscience, I have published a few papers in this area of word embeddings:
– 2015 Using text embeddings to identify geoscience synonyms to enhance a thesaurus, not just synonyms but also related terms. To my knowledge, this was the very first published paper applying text embeddings to oil & gas and geoscience) https://openair.rgu.ac.uk/handle/10059/1364
– 2016 Using text embeddings to suggest geoscience analogues https://www.slideshare.net/phcleverley/machine-learning-using-text-for-geoscientists-facilitating-the-unexpected-in-enterprise-search .
This approach of suggesting geological formation analogues using word vectors which I published in 2016 (above) was copied by Bayrakar et al (2019) on their paper on GilBERT https://openreview.net/pdf?id=SJgazaq5Ir . In fact the user interface display shown on page 3 is identical to that presented in my presentation above (3 years earlier in 2016). Although it was not acknowledged or referenced in their paper 🙂
Lee et al (2019) showed in the Biomedical domain with BioBERT, perhaps not surprisingly, training transformer models with domain specific text performs better than with generic text. https://arxiv.org/pdf/1901.08746.pdf
– 2017 Cross plotting text embeddings to surface geoscience knowledge hidden within a large corpus https://paulhcleverley.com/2017/05/28/text-analytics-meets-geoscience/
Other papers published on applying word vectors to geoscience include:
- Qiu et al (2015) Keyphrase extraction algorithm using enhanced word embedding here
- Ma and Zhang (2015) Using word2vec to process big text data here
Since 2013, numerous developments have taken place on language models (word2vec, GloV2, fastText, ELMo, BERT). In 2018 techniques emerged that were called NLP’s ImageNet (Machine Vision) ‘moment’, mainly in the ability to apply transfer learning and the benefits that go with this. These are summarized below in Table 1:
Table 1– Recent development on language models

More recent developments this year (such as Transformer-XL) have addressed the limitations of fixed length context windows and the ability to respect sentence boundaries and reference longer term dependency. These methods may offer opportunities to improve state-of-the-art performance of BERT for example.
In an interesting development earlier this year, OpenAI trained (10 GPU’s several months) a transformer-based language model (GPT-2) to predict the next word in 40GB (10 million articles in Reddit with more than 3 votes) of Internet Text. A significant scaling up of model size and flexibility compared to previous models.
According to reports, it was able to generate extremely plausible passages of text that match a given input style and subject matter. According to OpenAI, it had concerns on its potential malicious use, so all the results & models (very unusually in this space) were not made publicly available; or as reported by Forbes, TechCrunch and the Guardian ‘AI fake text generator may be too dangerous to release’. This touches on the ethics of advanced AI and is an active area of discussion and research.
OpenAI gave an example (Fig 3) of the type of text their model could generate given an input context (about unicorns). It is remarkably coherent (albeit gibberish).

Fig 3 – GPT-2 Generated text
In summary, it is likely that these language models present significant opportunities for geoscience industries, where geoscientists are already swamped, and have too little time to read all the available information.
Further reading
Mikolov et al (2013) word2vec: https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
Pennington et al (2014) GloVe: https://nlp.stanford.edu/pubs/glove.pdf
Bojanowski et al (2016) fastText: https://research.fb.com/fasttext/
Nooralahzadeh, F. (2017). Word embeddings using the Schlumberger Oil & Gas Glossary https://www.uio.no/studier/emner/matnat/ifi/INF9880/v17/materials/nooralahzadeh.pdf
Peters et al (2018) ELMO: https://allennlp.org/elmo
Devlin et al (2018) BERT: https://arxiv.org/abs/1810.04805 https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
BERT Online Demo https://gpt2.apps.allenai.org/?text=Who%20is%20
Dai et al (2019) Transformer-XL https://arxiv.org/abs/1901.02860 https://ai.googleblog.com/2019/01/transformer-xl-unleashing-potential-of.html
https://openai.com/blog/better-language-models/ OpenAI GPT-2
Radford et al (2019) https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
Padarian (2019). GeoVec: word embeddings for geosciences https://towardsdatascience.com/geovec-word-embeddings-for-geosciences-ac1e1e854e19
Bayraktar, Driss and Lefranc (2019). Representation learning in Geology and GilBERT https://openreview.net/pdf?id=SJgazaq5Ir
Hern (2019) https://www.theguardian.com/technology/2019/feb/14/elon-musk-backed-ai-writes-convincing-news-fiction

…but it’s not really AI inasmuch as it doesn’t really involve recursive learning… But maybe that is the Guardian’s use of AI, which is a lay digest for AI… Fake reporting…
From: “A Geodyssey – Enterprise Search & Discovery, Text Mining, Machine Learning Human Computer Interaction Research”
Reply-To: Machine Learning Human Computer Interaction Research
Date: Monday, 3 June 2019 at 14:09
To: Guy WF Loftus
Subject: [New post] Word embeddings and language models
phcleverley posted: ” Understanding a word by the company it keeps (Firth 1957) and the Distributional Hypothesis (Harris 1954) – words that occur in the same contexts tend to have similar meanings – are concepts that have been with us for over a half a century. However, in t”
LikeLike
Fascinating stuff as ever…
From: Guy WF Loftus
Date: Monday, 3 June 2019 at 16:11
To: Machine Learning Human Computer Interaction Research
Subject: Re: [New post] Word embeddings and language models
…but it’s not really AI inasmuch as it doesn’t really involve recursive learning… But maybe that is the Guardian’s use of AI, which is a lay digest for AI… Fake reporting…
From: “A Geodyssey – Enterprise Search & Discovery, Text Mining, Machine Learning Human Computer Interaction Research”
Reply-To: Machine Learning Human Computer Interaction Research
Date: Monday, 3 June 2019 at 14:09
To: Guy WF Loftus
Subject: [New post] Word embeddings and language models
phcleverley posted: ” Understanding a word by the company it keeps (Firth 1957) and the Distributional Hypothesis (Harris 1954) – words that occur in the same contexts tend to have similar meanings – are concepts that have been with us for over a half a century. However, in t”
LikeLike
Hi Guy Thanks. Reinforcement learning is not the only type of machine learning. It also depends on your definition of AI. Many see AI as simply mimicking or performing tasks that require human intelligence. Ten years ago voice recognition was a bit of a holy grail for AI – many may see this almost solved today. Goalposts change. You could split AI into ‘weak’ and ‘strong’. Most NLP/ML I’m discussing would fit into the weak AI part and academia tends to use more specific terms (e.g. Machine learning) rather than ‘AI’.
LikeLike
Thanks Paul.
LikeLike