

Platform Strategies Conference, National Union Building, Washington DC September 26-27 2018 Hosted by Silverchair.
Conference notes: Dr Paul H. Cleverley, Robert Gordon University, Aberdeen, UK
Introduction
Over 100 people gathered at the platform strategies conference this week, converging on the 1890’s Brownstone National Union Building in the Penn Quarter of Washington DC between the White House and Capitol Hill. The event was superbly organized by Silverchair (Jake Zarnegar, Stephanie Lovegrove and their colleagues) with an intimate feel often lost at larger conference venues.
With over 30 talks and sessions involving the likes of Taylor & Francis, Google Scholar, American Physical Society, Wolters Kluwer, American Chemical Society, American Psychological Society, Duke University Press, American Society of Clinical Oncology, JSTOR (and many more) I cannot do justice to all that was presented. Instead I will focus on the area I am most passionate about – so will present my own lens on proceedings. The full agenda and presentation to be posted on Silverchair site: https://www.silverchair.com/community/platform-strategies/
Culture and buy v build technology
Max Gabriel (Taylor and Francis) discussed culture and the Knoster model as a framework for leaders to look at change; change, confusion, anxiety, resistance, frustration and treadmill. Where unclear context, overestimation of capabilities, misjudgement of culture and underestimation of complexity are typical failings when trying to implement change in organizations. Tough conversations are not always had at the beginning of projects and ‘Agile’ ways of working won’t necessarily bail you out of trouble if those conversations are not had.
Mark Doyle (American Physical Society) discussed the benefits and challenges of building your own publishing and search technology using OpenSource rather than buying commercial offerings. Difficulties include adding new functionality and reliance on key people.
Stuart Leitch (Silverchair) discussed their own musings on whether to build their own bespoke technology or use existing off the shelf. It was stated that 70% of software costs are in the long tail of maintenance which is not always realized up front, and complex software needs a lot of internal people. A bimodal model to giving up some control was presented, ‘infrastructure as a service (e.g. AWS)’ and ‘Platform as a service (high level no access to OS)’ which force simplification. I especially liked the phrase “security is a tax on everyone!”.
Jim King (American Chemical Society) discussed the question of how much of what we (societies) do is competitive advantage? Societies like to think they are unique, but 70% of content delivery is probably the same. Cultural attitudes to ‘failing’ were discussed, with the comment made that failing is not a bad thing as long as it does not cost that much. In R&D, failing 70% of the time probably is ok, in implementation, if you fail 70% of time you are unemployed! Innovative organizational cultures have to have some appetite for risk/failure.
Jake Zarnegar (Silverchair) discussed the benefits of unifying at a product platform level for academic publishing. Such as spending more on what matters, instant site creation, surfacing underused products, brand reinforcement and user experience along with user intelligence. The challenges with a unified platform include risk concentration – all eggs in one basket and potential feature degradations.
Scott Henry from ASM International (the world’s largest association of materials engineers and scientists) emphasized discoverability of information as key for their books, journals, magazines and databases. Content enrichment (semantic tagging) and data analytics can enable discoverability and user experience, acknowledging that most people find academic content via Google Scholar first, then go to the publishers site.
Jasper Simons (American Psychological Association) have a multi-pronged approach to distributing their content; their own system and channels such as EBSCO, OVID. They have their own taxonomy and a sizeable staff for indexing to ensure content is categorized effectively. A number of user feedback comments were presented regarding use of their system/channels: “Users love the methodology filter and ability to search by grant”
The challenges with having your own technology are numerous: always catching up to mainstream techniques, have to have own tech staff, ongoing investment for hardware, developing our content is our real advantage not technology. The benefits of having your own technology include control of user experience, have deeper understanding of APA psychology content so technology can be tailored to the domain better than off the shelf, fast turn around on releases and flexibility on workflow integration.
In the discussion APA discussed that they had around 180 staff focussed on content and sales & marketing, with around 140 for technology and internal IT, as a ratio.
Allison Belan (Duke University Press) discussed how in the past books built reputation and journals made the money for publishers. This may be changing (at least for them) with revenue slowing for journals, meaning they may have met “peak subscription”. To adapt they are creating more granular offerings/slices (e.g. Gender studies, Latin American Studies, Religious Studies and Music & Sound), as well as different pricing models e.g. lease, pay per use, as well as custom e-books. The technology platform can be an enabler to slice and dice content to make it more attractive to customers that don’t want to purchase the whole collection for a single price. They demonstrated how easy it is to slice and dice content given an appropriate technology platform.
The age of mobile
Finishing off day #1 Tobias Dengel (Willowtree Apps) gave an insightful talk on mobile. Clayton Christensen’s The Innovator’s Dilemma was referred to, where disruptive breakthroughs are needed to maintain growth and ideally, an organization or industry can stack one ‘s’ shaped breakthrough on top of another to continue growth. But to do this they need to keep innovating.
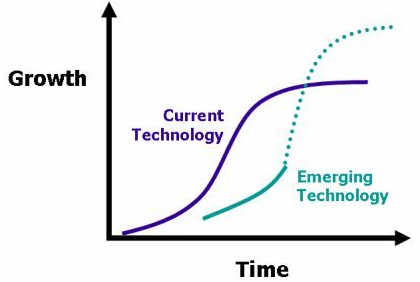
This actually reminds me as a geoscientist involved in oil and gas exploration, of the creaming curve in a geological basin. Every oil and gas play has a law of diminishing returns, get in first find the big fields, get in late and its just the small ones left. So for a basin (area) to keep growing and find more oil and gas, you need to find new plays (perhaps through a new geological model/theory or new technological advances). The Gulf of Mexico is a good example, with new plays (e.g. deeper below salt) historically rejuvenating the area. Oil & Gas Exploration is basically in the “ideas business”.
Technology has its own ‘basin’ so to speak and arguably mobile has changed everything. Comments were made (with the usual Steve Jobs reference) that it is not about the technology, but what people want to do with it. That customer centric ethos was what defined Apple.
On the topic of innovation it was stated that “creativity cannot be willed”. The famous “Building 20” at MIT https://www.youtube.com/watch?v=2O_NhKHa13A was referenced, where in over 2 years human knowledge was advanced by decades. The key factors for this (as well as having smart people) was their multi-disciplinarity and cramped working space, with a view that ideas are not a lightbulb moment, more a network. Making people bump into each other unexpectedly increases the chances.
These days usability studies, ethnography, focus groups and interviews are deployed by technology vendors in order to find the most promising idea. Prioritizing ideas is key. Care must always be taken (as any researcher will know) with biases such as the observer effect (simply by studying people we change their behaviour), priming people, acquiescence and hindsight bias – where we look back and believe an event was predictable (when it may not have been).
Voice search is now being used by 46% of Americans – essentially because it makes life easier. Some intriguing comments were made that whilst we may be able to listen at 130 words per minute (wpm), we can read at 250 wpm. So when we ask our phones what is on at the cinema, it is faster for us to speak to ask the question than to type, but it may be faster for us to read a list as a response of what is on, than listen to the answer. So the goal is not necessarily for everything to be voice, just verbally efficient.
In the discussion it was mentioned in scientific discourse, voice can have issues with Proper Nouns. Domain specific voice apps may emerge that cater for this. Overall, a fascinating insight into the world of voice and mobile.
New techniques in scholarly publishing and search & discovery
I presented on text and data mining in scholarly literature. Most of the material is on this blog, focusing on associations between concepts in a ‘text lake’ to detect unexpected patterns, rather than the traditional article ‘information container’ search. Showing math equations at 9am might have been a step too far for some!! However, I wanted to show people through a very simple example – that in essence there is nothing ‘magic’ about machine learning when its broken down into its simplest elements. These techniques may be underused with respect to applying to scholarly literature.
Pierre Montagano (Code Ocean) discussed how almost all publications have a computational component. Researchers are however, having difficulty reproducing their own work (code) let alone that of other researchers. CodeOcean ‘containerizes’ code with all its dependencies built on Docker/Linux (differing from GitHub). They support Matlab, OpenSource, a “reproducibility platform”. So researchers can publisher their code (and also make it available for peer review) as well as their usual paper.
Tatyana Unsworth (XSB/SWISS) discussed linked standards documents (Smart connected documents) using the Semantic Web for Interoperable Specs and Standards (SWISS). Boeing for example have 17,000 active standard documents, its complex! Linked data makes it easier to jump from a material specification to a part or process document referenced in that specification and this is important as standards get constantly replaced.
John Unsworth (UVA/Hathi Trust https://www.hathitrust.org/ ) presented. HATHI is a partnership of academic & research institutions, offering a collection of millions of titles digitized from libraries around the world. It includes those digitized by the Google Books project. Over 5 Billion pages. The aim is to provide computational access to this resource, whilst not moving the data/preserving copyright. They provide analytics tools for techniques such as n-grams and feature extraction for word trends. With 130 member institutions, ironing out security and other elements takes time, working with existing agreements not renegotiate new ones. Harmonizing metadata was a big first step.
Taxonomies and Ontologies
John Magee (Gale Cengage Learning) have over 1 Billion documents in their index and use a subject thesaurus of 60,000 preferred and 60,000 non-preferred terms. The importance of bringing things back to the user – ‘what do they want to do’ was made, before developing vocabulary and using Wikidata to automatically disambiguate non unique terms. Jabin White (JSTOR) discussed how search expectations have been changed by Google. An Oncologist would not walk up to a librarian and shout “cancer”, but that is exactly what they do to search tools!! Nice analogy! Google has raised the expectations we have for search outcomes. JSTOR services 1 million queries a year, which is dwarfed by Google’s 1.2 Trillion. Less usage data to work with.
It was stated that Humanities and Social Science content is used differently to Science, Technical and Medical (STEM), with the former not concerned so much with a ‘right answer’. Search then Browse was discussed as the typical workflow, but browse was considered poor. An exercise was undertaken to munge 4 different taxonomies together, automated text mining used to help this process and results indexed in SOLR. The ‘Text Analyzer’ tool was shown that allows a user to drag in some text and the tool uses LDA Topic Modelling (Blei 2002) to see if any matches exist to thesaurus and then uses these to suggest content.
Travis Hicks (American Society of Clinical Oncology) discussed how personalization has been added to taxonomy to tailor their technology platform experience for the 46,000 society members. Combining user reported data from profiles, with automatically collected data (e.g. what papers a user read, conferences attended) to suggest and tailor content through weighted algorithms on topics. In a survey of 3,200 staff at the annual meeting, 73% felt the suggestions offered were favourable. This blurs the line with respect to content, not just about journals and books, but also education – what sessions to attend at the conference. I had not thought of this before.
Michael Clarke (Clarke & Esposito), Paul Gee (JAMA Network), Mike Mutka (Straightaway Health Careers/Relias) and Anna Salt Troise (American Academy of Orthopaedic Surgeons) discussed digital education. I cannot do this fascinating session justice, but clearly personalization and content is seeing a convergence with education and journal society content. Education and Healthcare are also key area for developing (any) countries.
Search Aggregators and Next Generation Search
Anurag Acharya (Google) gave a fascinating talk on Google Scholar of which he was a co-founder. He discussed how scholarship in general was behind on ‘mobile’. Reading takes time, but finding and scanning need not be. The slow workflow of linking to information, DNS resolving is one reason that holds scholarly publishing back. As of March 21st 2018 Google Scholar has implemented pre-fetching of abstracts to speed up this process. Publisher branded abstracts embedded within search results is now in place for the likes of PlosOne, Highwire, JSTOR, Nature, Emerald, Springer. This has seen growth in views by a factor of 2.
Last year (2017) to cater for experts and non-experts, Google Scholar introduced topic maps for query suggestions. This provides guidance based on query sophistication. So if a user makes a query on ‘carcinoma’ they will receive general query suggestions. A query on ‘renal carcinoma’ will receive more specific query suggestion and a query for ‘renal carcinoma nephrectomy’ even more specific query suggestions.
I was particularly interested in this, as I had published a paper in 2014 in the Journal of Information Science (JIS) noting preferences for this phenomenon amongst petroleum geoscientists and engineers. Those making a broad query (e.g. corrosion), prefer broad query suggestions, those making a more specific query (e.g. stuck-pipe), prefer more specific query suggestions.
This may well be a best practice that all search tools should adopt?
Ruth Pickering (Yewno https://www.yewno.com/ ) discussed the 2016 Davos World Economic Forum work stating that next generation search using AI was a market worth $1 Trillion. By 2026, next generation search may be worth $10 Trillion. Paraphrasing Marchionini (2006), Ruth discussed directed search (there is a right answer) and undirected ‘discovery’ or exploratory search (no right answer) which is their target market using Knowledge Graphs visualization technology. User engagement (a fun experience) being key for this type of search. This touched on my ‘serendipity’ whilst searching interest.
In the discussion some comments were made on how well visual methods to search for information over and above ‘a list’ get user take up. Google has its own experiences (remember the Wonder Wheel) that was ultimately dropped as evidence suggested mass take up of visual tools does not happen because of the additional cognitive load involved. But its good we keep trying and test this hypothesis with new visualizations. Some comments were made that taxonomies and ontologies would be replaced with automated AI rather than manual curation and maintenance. I agree in part (for semantic relatedness networks). But I feel for semantic similarity (“is-a”, “part-of”) aka a taxonomy, supported by the IR/AI literature, automated techniques cannot (yet?) build accurate deep domain taxonomies.
Jan Reichelt (Kopernio https://kopernio.com/ ) one of the founders of Mendeley, discussed the Internet browser plug-in Kopernio to solve the problem of people being redirected from search tools like Google Scholar, to a publisher, then to Athens/Shibboleth, to another site – when they just want the PDF! Sometimes researchers then go to sites which may break copyright rules – path of least resistance – principle of least effort (Zipf Law). Evidence shown of 25-40% additional downloads redirected to publishers sites where this plug-in is working.
The final session involved a roundtable on the future with Brian Crawford (American Chemical Society Publications), Tom Easley (JAMA Network), Jayne Marks (Wolters Kluwer Health), Alix Vance (GeoScienceWorld) moderated by Ann Michael (Delta Think). This was a closed session so I am unable to report the discussions – but they were lively!
Summary
User expectations for search are driven by consumer tools like Google. Scholarly societies are struggling to keep up and are weighing up the benefits and disadvantages of internally building their own search & publish technologies using OpenSource as opposed to customizing commercial platforms. Online education and personalization for society members is increasingly converging with traditional publishing. Mobile could potentially change many things. Handling security and copyright with many stakeholders is also major issue and takes time when trying to open up digital repositories to new approaches.
Some societies/publishers are seeing ‘peak subscription’ and are looking for innovative ways to slice and dice their existing content, or create new ‘S’ shaped innovations such as Linked Data, Text and Data Mining (TDM) including Machine Learning (ML) leveraging their content for new growth potential. Some societies may have to look for savings in other areas in order to fund new ‘S’ shaped innovations and/or partner with others.
When the scholarly community comes together as one, they can potentially deliver changes that have significant impact across the industry (such as Crossref https://www.crossref.org/). A number of areas provide potential fertile ground for the next landmark change in scholarly publishing which may be imminent, although history tends to tell us we can’t always predict what or when the next ‘S’ shaped event will be…

Leave a comment