
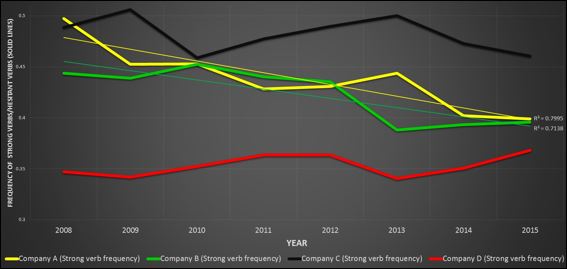
I presented at the International Society of Knowledge Organization (ISKO) this week, sharing findings of an exploratory study. A Knowledge Organization System (KOS) was automatically applied to the annual company reports of four similar sized oil and gas companies to detect forward-looking strong and hesitant sentiment, in order to detect rhetoric, social phenomena and predict future business performance.
The “Discovery” part of “Enterprise Search & Discovery” is arguably downplayed in much of the existing academic and practitioner literature. In addition to finding what you know exists (or finding document ‘containers’ that you did not), there may be a case to embed various sentiment algorithms as standard in enterprise search & discovery technology deployments. Designing with ‘serendipity in mind’, this may move the intent of a deployment from one of pure retrieval, to one of pattern recognition. Where ‘trace fossils’ may exist in the information aggregate, not discernible from any single document.
The utilization of such algorithms to ‘compare’ and ‘contrast’ perhaps in a web part in the user interface, may move the enterprise search & discovery tool further up the Bloom’s Taxonomy pyramid, in assisting higher forms of thinking (along with delivering the surprising). It may not make sense for many queries made in general purpose ‘Google-like’ search tools deployed behind a company’s firewall, but detecting queries which do could be a useful undertaking. As described in a previous post many things can have a ‘sentiment’ which may act as a catalyst for further inquiry and potential new learnings. Whilst sentiment analysis is a useful technique when you have an a priori hypothesis in mind, it could well surface interesting phenomena even when you don’t.

Wow! Such a informative post. Sentiment analysis gives us the opportunity to know the opinion of the customer and Its also helps a lot for research a market. Thanks for such a informative post.
LikeLike