
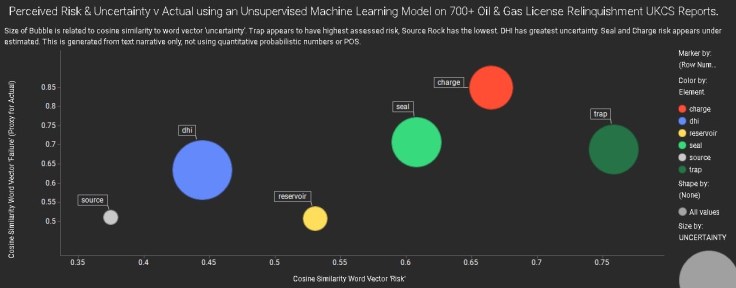
Using over 700 public oil & gas license relinquishment reports from over 30 companies (2008-2017) in the UKCS, I built a language model of similarity between terms after careful semantic processing.
The chart above shows vector cosine similarity between various play elements and the ‘risk’ word vector on the x -axis, and ‘failure’ (proxy ‘actual’ i.e. for dry hole/eq.) word vector on the y-axis. The size of the bubble is the similarity to the ‘uncertainty’ word vector.
Averaging is smoothing out some subtleties per basin/company, but its interesting to see a few things from the patterns in the whole text collection as opposed to quantitative risk/COS probabilities.
Trap appears to have the greatest assessed ‘risk’ (highest vector cosine similarity to risk) which matches outcome. DHI has the greatest uncertainty. Source (as in a mature basin) is comparatively low risk here. Charge and Seal risks may be systemically underestimated – given the text narrative.
This uses automated complex word co-occurrence in the narrative descriptions, not the assigned numerical probability used in the reports. Latent patterns hidden in full sight.
Lots of caveats, subtleties and more work required. Could be a useful technique to ‘challenge’ risking, POS and bias perhaps.
In the algorithm economy it has been said that most algorithms are simply opinions dressed in code. Even the textual content used to train machines is often subjective (and can be chosen subjectively). Nevertheless, why wouldn’t you want to know the ‘opinion’ from an AI machine that has read everything? 🙂

Leave a comment