
One of the key tasks in Natural Language Processing (NLP) for the Petroleum Geoscientist is detecting entities in text, such as ‘source rock’. The challenge is that just using the term ‘source rock’ and it’s plural form ‘source rocks’, would miss 22% (recall) of all occurrences (false negatives) for ‘source’ in its word sense of ‘source rock’. This is because everyday parlance in text for ‘source rock’ often involves dropping the ‘rock’ part and just using: ‘source’, ‘sourcing’, ‘sourced’ and ‘sources’.
For example, “The reservoir may be sourced by underlying Devonian marine shales“.
The problem is that the term ‘source’ need to be disambiguated even in the narrow domain of Petroleum Geoscience. Sometimes the narrow domain of text used can ‘self disambiguate’ of a sort, and remove the need to differentiate other meanings. For example, if you were analysing well drilling information, you would not need to disambiguate ‘fishing’ (retrieve an object from a well) from other senses, as it is unlikely those other senses will be present in the narrow domain text you are analysing.
However, the term ‘source’ is polysemic (many meanings) even in narrow geoscience information, so false positives will likely be present in an extraction. For example even in petroleum geoscience texts, ‘source’ is commonly used in the sense of sediment transport, magmatic & volcanic provenance, mineralogy, gravity & magnetics sources, seismic, provenance of data/information etc.
For example,
“The source of data for the reservoir was I.H.S. Energy“.
“The sandstones were sourced from the uplift to the north“.
“The magnetic source was close to the surface”.
It was found that without disambiguation, 22.4% of all mentions for ‘source’, ‘sourced’ and its syntax variants in Petroleum Geoscience texts were not related to a source rock. This means an extraction without any Word Sense Disambiguation (WSD) will likely give a precision of 77.6% with therefore 22.4% false positives.
In other words, one in five extractions from text will most likely be wrong.
Part of Speech (POS) tagging can sometimes help, but in many cases it cannot. In this situation, ‘source’ and its variants can be used as nouns ‘NN’, noun plurals ‘NNS’ or verbs ‘VBZ’ past participle in equal measure whether it is referring to a source rock or not. So this cannot help us in this situation.
Machine Learning Model
Using thousands of representative labelled examples, a Support Vector Machine (SVM) and Multinomial Bayes were used in a machine learning pipeline (Vectorizers and Transformers), taking into account word order, to create three statistical models. An ensemble approach was used to compute the weighted sum of the predicted probabilities of the three models for each class. The resulting statistical classifier achieved an F1 score of 94.52% (see below Fig 1) which outperformed the accuracy of any single model.
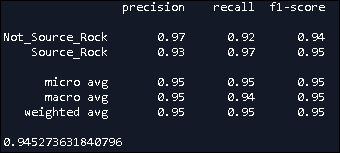
Fig 1 – Precision, Recall and F1 Score for Classifier
The resulting Python binary pickle model file (for this and other terms that need to be disambiguated) can be called in one line of Python code and integrated into any existing NLP pipeline: so given any sentence or passage of text containing the word ‘source’ (‘sources’, ”sourced’, ‘sourcing’) it will return a prediction whether the text relates to ‘source rock’ or not by using the context in the text.
This is useful to aid extractions in order to populate XML/JSON document headers, or populating a KnowledgeGraph or a simple CSV export. These can then be combined with other algorithms and semantics (e.g. other clues to potential source rocks such as ‘carbonaceous shale’) to detect potentially hidden plays & opportunities in text.
This could represent a step change in extraction in this niche domain area. The benefits for Geoscientists could include making new connections and ideas from subtle patterns we normally bypass in volumes of text too vast for a Geoscientist to ever read.

I thought you might find this paper of interest…
The search for suitable mathematical representations and specific models requires a large amount of representative corpora in the O&G domain. However, public access to this material is scarce in the scientific literature, especially considering the Portuguese language. This paper presents a literature review about the main techniques for deep learning NLP and their major applications for O&G domain in Portuguese. — https://arxiv.org/ftp/arxiv/papers/1908/1908.01674.pdf Your thoughts?
LikeLike