

I was asked recently by a Chief Information Officer (CIO) of a large organization, where does search end and text analytics begin? It is an interesting question perhaps worth exploring and developing some models, one of which is shown below (Figure 1).
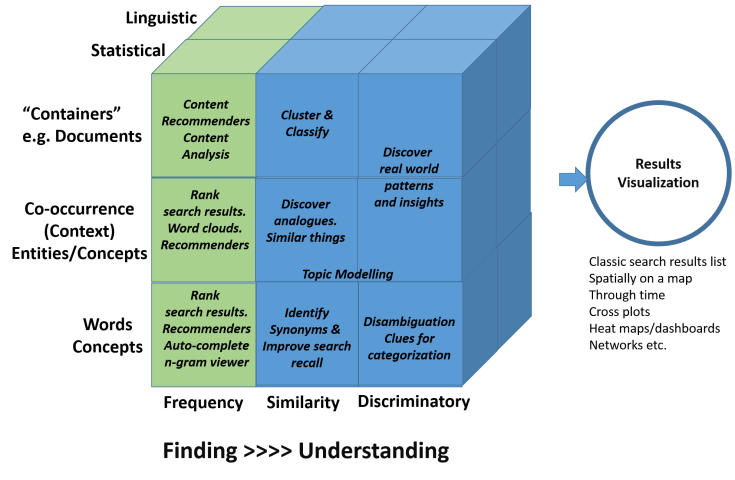
Figure 1 – From ‘traditional search’ (green) to unlocking a wider range of questions we can ask
The green boxes (Figure 1) are the domain of traditional search and the blue boxes illustrate the direction of travel being taken by some organizations blending increasing amounts of text analytics and Knowledge Organization Systems (KOS) like taxonomies and thesauri to traditional Information Retrieval (IR). From left to right, this allows organizations to move beyond just finding documents which contain existing ‘knowledge’, to pattern recognition (where the searcher is part of the process) discovering latent ‘knowledge’ directly, sometimes using the whole corpus of text available.
Whether you call this space Knowledge Management, e-business, Artificial Intelligence (AI), smart machines, deep learning, cognitive computing or plain old search & discovery probably does not matter.
Ranking by frequency dominates
Text has been converted into numerical representations of some form since the first search engine was developed. Statistical approaches for search have generally been dominated by frequency. Whilst different metadata fields are typically tuned with different search ranking criteria (e.g. title and tags higher weights compared to body text), all things being equal its statistical frequency that dominates ranking. Whether that is how many times search terms have been mentioned in a document/corpus or how many times people have made certain search queries (for query suggestions as you type) or how many times a web page or document has been referenced or accessed. Even facets (refiners) typically shown on the left hand side of a search user interface to help narrow a search, are almost always ranked by frequency or popularity, regardless of whether they are created from manual or automatic tagging methods. Ranking by frequency dominates.
I won’t delve into ‘relevance’ in this article, needless to say ranking by statistical frequency has been used as a part-surrogate for relevance.
Linguistics
Linguistics (including the use of authority lists, thesauri/taxonomies, ontologies for handling synonyms & relationships and Natural Language Programming (NLP)) have been used for decades to improve searching. These techniques are typically used to ensure the above methods operate on ‘concepts’ to mitigate the ‘vocabulary problem’ we have as humans and improve search recall and precision. Thesauri, taxonomies and ontologies can also help recommend search terms. They are an aid to the statistics, with many scholars proposing a ‘best of both worlds’ that hybrid (linguistic & statistical) techniques work best to cater for a range of scenarios’ in search and auto-classification, although some still argue for just one or the other.
Social cues
Social analytics has been used in search for many decades. For example, recommending or boosting an item in search results because it is viewed or cited very often, suggesting search terms as you type “the Google type model” or suggesting another information item that may be of interest, the “Amazon.com type model” (often called crowdsourcing). These approaches are transactional, based on the social cues from people. Enterprise social tools increasingly hosted in the cloud, perform the same type of analysis, using the data from document or post views and likes, ‘people who attend online meetings that you attended’ etc., to algorithmically push information to the user in an activity feed like the “Facebook type model”, complementing traditional enterprise search. Aspects of personalization in browser cookies have been doing this for years of course, by clickthrough advertising revenue.
It could be argued that search has never been separate to analytics.
Content Analytics
As information volumes have grown exponentially, so has the analysis of the content inside these ‘containers’ of information, such as web pages, documents and structured databases. Linguistics is still a very important part, but it supports the statistical methods that are used to seek out ‘interesting’ situational context.
Taxonomies and semantic networks are useful, if not essential for computer systems to help us discover information, however, they may also blind us to new discoveries if we ignore what the data (text) is telling us and only superimpose a priori representations.
Organizations have turned to auto-classification to help records retention, to reduce file storage costs and clean up Redundant, Obsolete and Temporary (ROT) files typically on the shared file system and email systems. Search is also used for reporting, highlighting information in the corpus that should not be there for legal, privacy or confidentiality reasons. This analysis may often be simply a series of phrase queries. Similar techniques have been (and continue to be used) automatically moving emails into spam folders when they contained certain trigger words or with disambiguated semantics. Perhaps these approaches are akin to First generation content analytics.
Second generation analytics could be viewed as more advanced techniques which target business value, wealth creation and risk reduction to surface real world patterns. In addition to frequency, both similarity and discriminatory techniques are increasingly used. In these techniques conversion of text to numerical form is taken to extremes. For example the creation of complex probability distributions using neural networks approximating one words relationship to every word in the entire corpus where vectors can be compared, added and subtracted.
Instead of using this analytical information to influence search results of document and web pages, the focus shifts to the associations between concepts and entities within and across those documents and web pages. From documents to entities & concepts. It is still ‘search’ but a different focus.
Using an analogy, if documents are “atoms”, content analytics smashes them apart to look at the concepts & entities “particles” inside and their behaviour with respect to one another. You might find a new particle or a new relationship between particles that you did not know before, but you have to look inside first and it takes imagination and energy to produce the really exciting.
Analogues
Organizations are increasingly interested in how these content analytic techniques can be used to identify complex business analogues. As one scientist made the comment, “analogues are difficult to search on because you don’t know what they are, so you don’t know what search queries to use!” For example in the oil and gas industry looking for geological environments (using the similarity of words that appear around different entities), and/or surface an activity trend that one company is doing in a geological basin, that other companies are not. These techniques can transform unstructured information into structured information to automatically return answers (not lists of documents), to stimulate ideas, visualize results on a map or store in a database.
Prediction
Coping with information overload and keeping on top of what is going on around you is getting increasing difficult in many areas. Using historical information to calibrate systems, may help predict certain types of events before they happen. For example, looking at patterns from daily operations reports as clues, alerting engineers to potential impending issues. They present another voice based on the text, akin to “Look, last time I saw these clues appearing in the operations reports..this happened”. These techniques have been used with quantitative data for many years to predict and prescribe action, but are now being increasingly applied to qualitative (unstructured text) authored by people.
Relevance versus Interestingness
In some recent research on facilitating serendipity in the search user interface, a scientist in an oil and gas company mentioned a search result refiner was ‘relevant but not interesting’. Clearly what is interesting for one person, may not be interesting for another. However, there may be a need to move beyond traditional definitions (and algorithms) for relevance (Figure 2).

Figure 2 – Moving search beyond a text box and ten blue links
Summary
Returning to the question posed at the beginning, ‘Where does search end and text analytics begin?’
Perhaps they are two sides of the same coin. Text analytics has always been essential to basic information retrieval, although its main use was to help people find results (containers) they were looking for. Analytics of social cues have been used to good effect to help people locate what they were looking for and also discover information that they were not looking for. However, some argue this is discovery through the ‘rear view mirror’ and creates a filter bubble that does not encourage us to stray from the beaten path. Combining search and content based text analytics presents us with opportunities to help us formulate our needs, test hypotheses, predict events, unlock new knowledge and increase the propensity of our user interfaces to stimulate fortuitous information discovery.
There are likely challenges for the CIO. How to meet existing complaints and needs (to find that single web page or document) for all staff, whilst delivering the capability for advanced discovery to small communities that may wish to mine external and internal information (much more than a simple e-discovery solution) – which may lead to leaps in business value that cannot be predicted in advance. Many organizations have already done this organically. It may be a mistake to think this can be achieved with a single technology or user interface.
That brings further challenges with regards to costs, multiple indexing streams and complexity. Business cases and creative architectures may exist however to meet both requirements. However, this will require leadership, to set out a clear vision with careful planning and architecting. These decisions need to be made against a backdrop of technology vendor propaganda and useful information which are intertwined, making it sometimes difficult for objective and realistic views of what is possible and what are the caveats.
Exponentially growing information volumes combined with proven techniques published in the public domain, present an opportunity to expand our horizons; ‘To move the goalposts’, with respect to the questions we can ask computer systems and what those computer systems can suggest to us; after all, we may be asking the wrong questions.
Article with extensive references: http://www.slideshare.net/phcleverley/where-does-enterprise-search-end-and-text-analytics-begin
More at: www.paulhcleverley.com

Leave a comment