
Data driven discovery: It may be interesting to compare the similarities of minerals based on their co-occuring words in large amounts of archive geological reports, to actual known reported mineral occurrences in databases such as Mindat. One could perhaps easily automate this algorithmic comparison, leaving ranked “candidate” mineral associations not present in reference databases. There will be data artefacts for sure, but it may also trigger some ideation where a mechanism may be postulated.
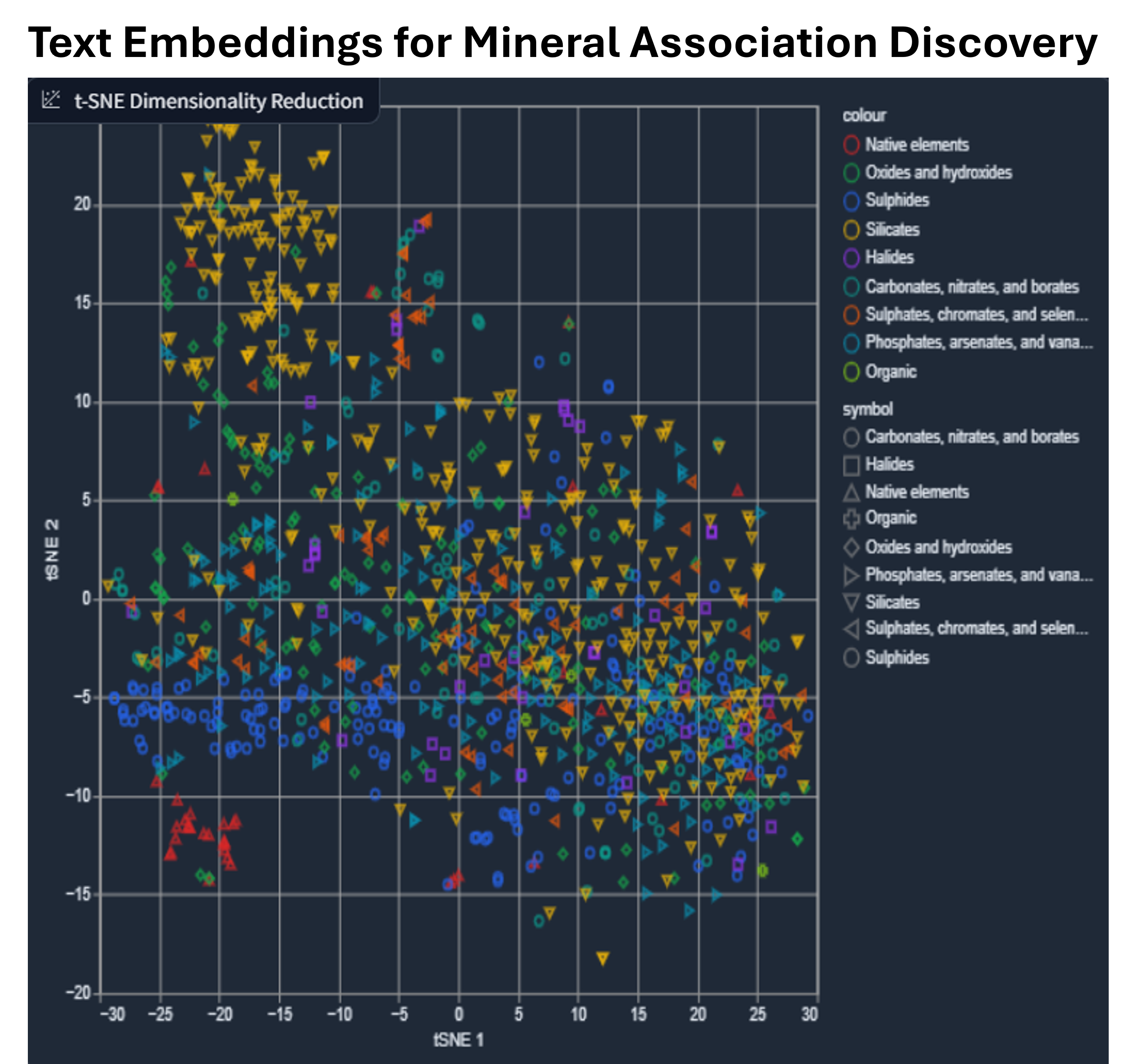
Text embeddings (dense vectors) were generated from many thousands of public geological reports using unsupervised machine learning. The similarity of 7,000 mineral names were compared, the dimensionality reduced by t-distributed Stochastic Neighbour Embedding (t-SNE).
It could be possible that outliers and associations are surfaced between minerals from combining vast amounts of archive literature, that are not well known or perhaps known at all – which may present areas for new investigations and hypotheses. It might also generate potential indicator associations or associations not typically considered for exploration.
A key point to note for those not familiar with text embeddings. One can generate similarity even if the mineral association is not explicitly mentioned in the text, as we are looking at dense vectors generated from the entire corpus not keywords.
Lawley, Morrison and other researchers have published interesting work on this mineral data discovery topic. I have been experimenting with rock classifications out of interest and will post on that shortly.
hashtag#geology hashtag#minerals hashtag#mineralogy hashtag#geosciences hashtag#earthsciences hashtag#subsurface hashtag#machinelearning hashtag#naturallanguageprocessing hashtag#artificialintelligence hashtag#ai hashtag#datadiscovery hashtag#analytics hashtag#bigdata hashtag#miningexploration hashtag#mining hashtag#criticalminerals hashtag#energytransition

Leave a comment