
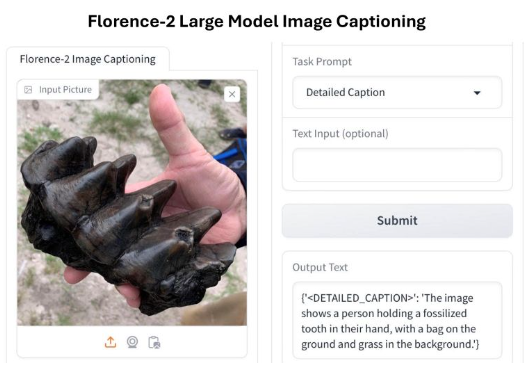
Experimenting with Florence-2 image captioning. It does a good job in this example predicting its a fossil tooth. I would have been even more impressed if it described it as a Mastodon tooth but that is where domain training may take over. You can try for yourself in Huggingface to test the capabilities and understand limitations. Link in the comments.
“Florence-2 [from Microsoft] is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages our FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model’s sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.”
The Mastodon tooth emerged from the Peace River in Florida using a shovel into the gravel. Mastodon’s are related to elephants and mammoths. It is postulated that they went extinct around 13,000 years ago possibly through climate change and also human predation.
Demo here: https://huggingface.co/microsoft/Florence-2-large

Leave a comment