")

I’ve been experimenting using text embeddings to generate sentiment of a corpus of documents. In this approach it is generated by geological age (but can be other contexts). Taking any input query e.g. “aquifer” then combining that (adding vectors) with geological age vectors and comparing to the cosine of the vector of various sentiment themes, then summing all the hyponym vectors to get the visual bar plot by geologial period/era. The actual sentiment vectors detected are also displayed to allow drill down to the evidence e.g.
Albian>Cretaceous>Good Quality>Positive
Bajocian>Jurassic>Unusual>Interesting
…
By applying these approaches to large volumes of text, we may reveal patterns that are not what we expect, potentially leading to new theories, ideas and learning events.
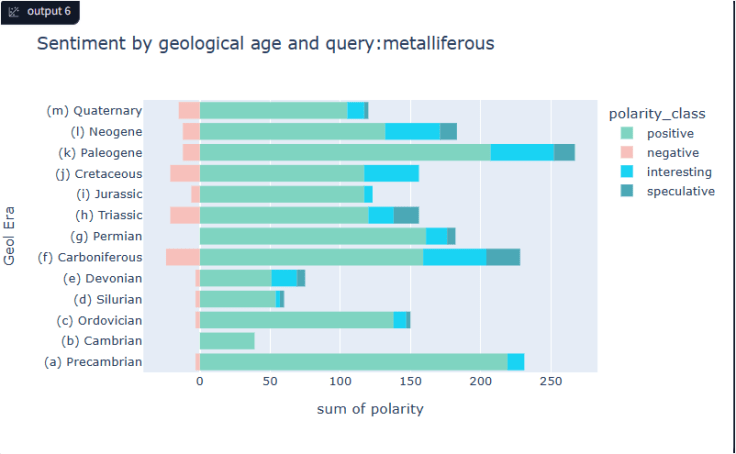
Above – sentiment for the query ‘metalliferous’ within the USGS corpus
Below – comparing sentiment by basin


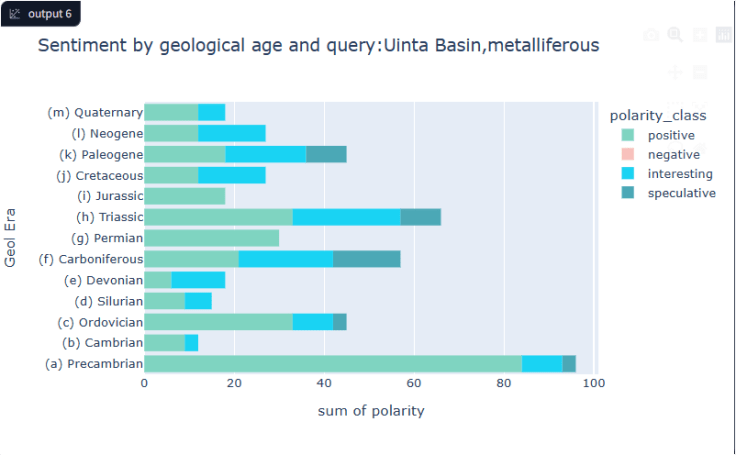
The sentiment is scored depending on the cosine similarity differences. I’m in the process of comparing these results with actual counts where sentiment is applied per sentence, to describe the pro’s and con’s of this approach compared with others.
#naturallanguageprocessing #artificialintelligence #subsurface #unstructuredtext #datadiscovery #analytics #geoscience #geology #geosciences #earthscience

Leave a comment