
I’ve been experimenting using text embeddings to identify relative topic emphasis in text corpora, as an example of similarity based unsupervised machine learning.
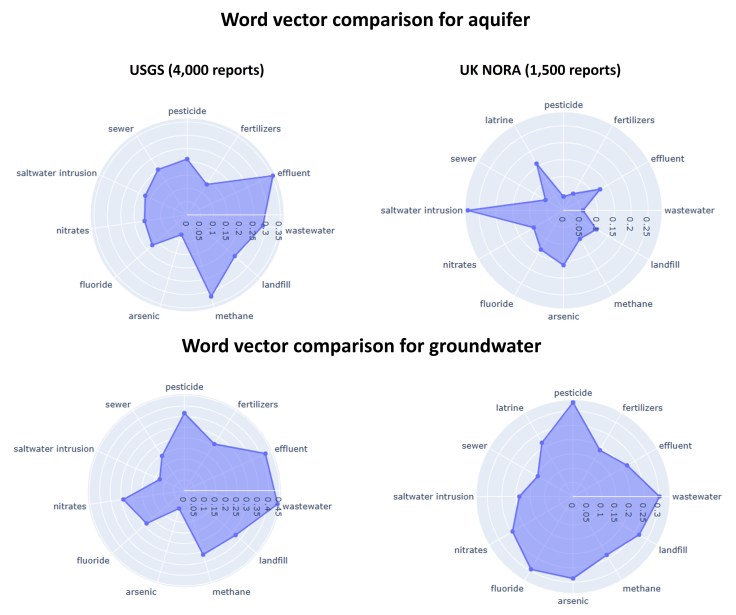
The examples below show the relative similarity of the word vectors for ‘aquifer’ (top) and ‘groundwater’ (bottom) to word vectors of various forms of contamination, comparing the US Geological Survey public collection (left) and UK NERC Open Research Archive (NORA) (right).
The topics are grouped roughly clockwise agriculture, industrial, natural and urban.
These techniques can be applied per document along with other techniques such as zero shot learning and Topic Modelling. In this example they are applied to whole text collections.
If we combined these two corpora together, we can create another set of text embeddings which would combine both, smoothing out these nuances.
Philosophically, you could think of building text embeddings as twofold. Firstly “lumping” all text together to narrow in on a single embedding for domain concepts and secondly, “splitting” to keep the finer detail (and differences) within corpora tying the embeddings to a specific source.
It’s not a tyranny of the ‘or’ – you can do both of course depending on use cases. When it comes to text embeddings, there is not a single truth.

Leave a comment